
It’s been 25 years since the fictional Skynet became self-aware and launched nuclear missiles against the humans who, in a panic, tried to disconnect it. However, in reality, the ability of AI systems has been very limited. At roughly the same time as Skynet was destroying the world, I was starting Orb Data and the monitoring systems we were implementing at the time were very limited. It wasn’t until the Tivoli Enterprise Console (TEC) that we could build any intelligence into alerts via the use of rules and this largely has remained the same until the last few years when finally we have seen companies such as Instana and Turbonomic bringing real AI into the process. But what does this mean for monitoring systems going forward? Can we finally forget about thresholds and when can we also remove human intervention too?
Thresholds Don’t Solve the Problem
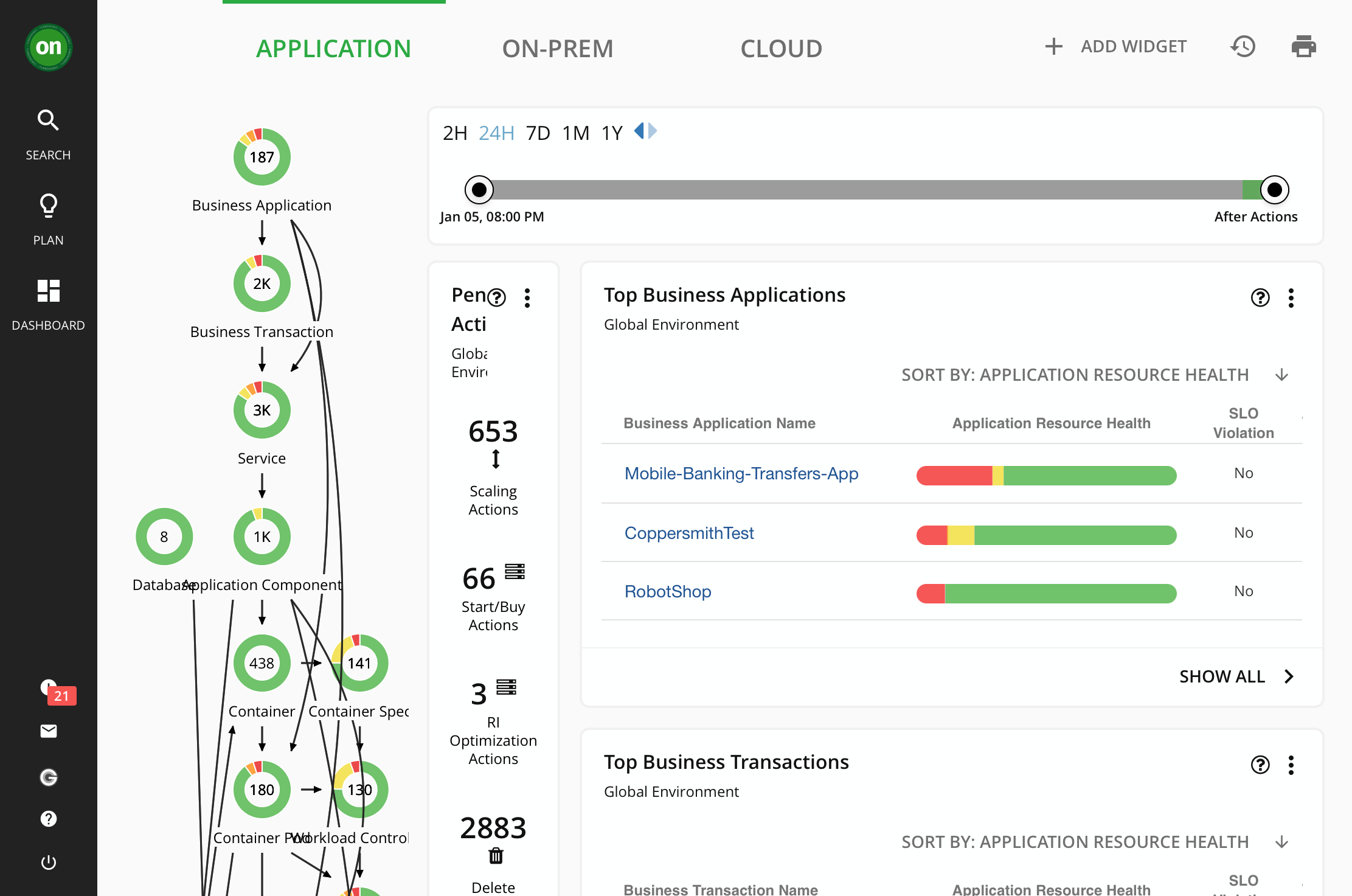
Over recent years companies are looking at containers to improve application lifecycle management. However, container platforms will not natively assure your services meet Service Level Objectives (SLOs) and cannot dynamically manage resources. They will attempt to ensure the services are available by spinning up a crashed container but if you want a good user experience, the system needs a lot more than just a new container to stop performance degradation.
In traditional monitoring we use thresholds but using threshold-based policies will not necessarily help because the speed of change in container platforms and uncorrelated autoscaling can end up causing problems. For example, if you set native horizontal autoscaling you will need to decide what metric(s) to monitor, and which thresholds to configure at upper/lower limits for every service deployed. If you have many services for an application the policies may not correlate with each other and so solving one issue may introduce another further down the road.
Therefore, the solution to meet your SLOs is not to set thresholds and alerts but instead to use elastic infrastructure so that the services are performing how your customers would like. However, to do this successfully you need automated analytics that continuously manages demand, supply, and constraints. This is where IBM’s new acquisition Turbonomic comes in. Turbonomic looks at the real-time application demand and accounting for constraints and interdependencies at every layer of the stack (from the logical to the physical), determines the right actions at the right time to ensure applications always get exactly what they need to perform. No thresholds and no humans.
No Humans
Turbonomic is the only platform that continuously assures the performance of the services it manages. The Turbonomic AI engine uses multiple metrics and cloud constraints in its analysis to generate fully automated out-of-the-box actions that will improve your application performance and reduce costs at the same time. Of course, these actions can be run manually too but with Turbonomic there is no need. And because of the trust Turbonomic users have in the suggestions they tend eventually to fully automate actions in the platform.
Turbonomic will never execute actions automatically unless you tell it to. To change this behaviour Turbonomic uses policies that by default will not run anything automatically. When you first see the pending actions, you execute many of them to see immediate improvements in performance and utilization. Over time, you develop and fine-tune your action-handling process to meet productivity goals and respond to changing business needs.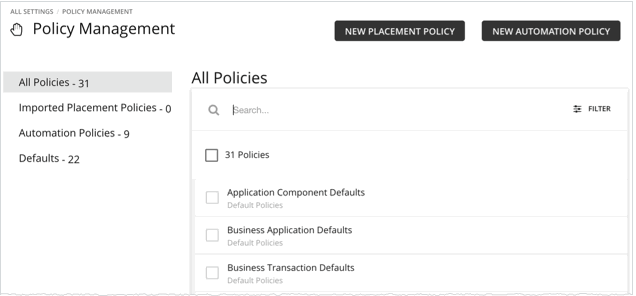
These policies allow you to:
- Disable actions that violate business rules. Turbonomic will not consider recommending disabled actions when it performs its analysis.
- Continue to let Turbonomic post actions so you can execute them on a case-by-case basis.
- Allowing certain actions to execute automatically.
Probably for most people reading this you are thinking the last option is a step too far. Only a few years back companies were reluctant to even have auto-ticket generation so how can they allow the software to manage their cloud services? To help you think about this Turbonomic suggests a multistage process which for brevity for this blog I have created a précised 7 stage approach.
- Visibility: Identity and aggregate all cloud subscriptions so that you can understand the overall spending and commitments made to the cloud providers. This should also include tagging the different workloads based on their purpose, owner, and environment (prod, test, dev, etc.)
- Low Hanging Fruit: A significant amount of savings can be made by closing unused resources such as idle unneeded VMs, unattached volumes, and old snapshots.
- Scheduled suspension: Suspension of non-prod workloads when they are not used can yield substantial savings.
- Manually Execute Actions: Review every action to validate its accuracy with stakeholders such as IT/Cloud Ops, Application Team, and finance experts. Once it’s run you can validate the impact to increase the confidence.
- Approval workflows: The next step is to implement an approval workflow with your ITSM solution (such as ServiceNow). The appropriate owner can then approve or reject the actions as they are suggested.
- Maintenance/Change windows: Define a weekly change window where all approved scale actions will be executed. Over time, this could change to a daily change window.
- Enable Real-time Automation – Finally, once you trust the suggested actions enable real-time automation.
This cycle should be run on pre-prod to start with to help to build confidence.
If you are interested in starting this process, seeing a demo of Turbonomic in action, or simply just have a question then please send me an email at simon.barnes@orb-data.com or leave a comment below.
Views: 329