
Many years ago, I wrote a workshop and a corresponding whitepaper on the business case for moving from the Tivoli Enterprise Console (TEC) to Netcool OMNIbus. It proved quite popular, and I ended up presenting this for IBM at a few user groups around Europe and a slightly longer hands-on workshop many times at Orb Data’s offices. The reason for its popularity was because there was a good ROI for this migration due to the efficiency and high availability features included in the newer product and so the costs for migrating to OMNIbus could be offset pretty quickly. I also wrote an internal cost justification for a large UK bank so that they could budget for the migration which they later performed.
More recently I saw the similar potential cost savings in IBM’s new Watson AIOps product and created a Webinar called “The Business Case for Watson AIOps”. Again, this Webinar was popular and as well as the original online presentation we’ve now presented a shortened version of this directly to customers so that we could take the discussions further. However, this time rather than write an accompanying whitepaper as I did previously I’ve decided that a better format is a blog. I hope you agree.
What are the issues AIOps tools can resolve?
For any business case there has to be an issue that you are trying to resolve or a cost that you are trying to remove and so before we start we need to look at what these are for an AIOps product. In this case there are 5 that any AIOps tool should be helping to resolve:
- Skills Shortage – Before the pandemic began, a report from Luminate stated that a third of vacancies (33%) in the UK were considered hard to fill. This may have changed over 2020 for obvious reasons but even so there is still a constant battle for all companies to not only employ good quality staff but retain the ones they have that often have a lot of the knowledge of their applications. There is an often quoted statistic that 10% of the staff have 90% of the critical skills and whether this is true or not it is certainly the case that many companies rely on a very few people to hold the expertise on their products and applications.
- Reliability – Gartner typically cited downtime cost at $300K per/hour. This will clearly change based on the characteristics and size of your business and environment (i.e., your vertical, risk tolerance etc.) but keeping systems up and ensuring their reliability is key to reducing these costs.
- Opportunity & Brand – Thirdly if there is an outage how does this affect the brand. We can all think of examples of companies that have had downtime which have made us think twice about using them going forwards.
- Tools – A trend I’ve noticed over the last 10 years is for companies to buy point solutions from many providers to plug each issue they find and then expect the staff to be experts in them all. Even if an employee does become an expert they still have to hop between the tools and waste time as a result. They also make themselves so valuable that they become expensive to keep and often leave.
- Financial Risk – Clearly an outage costs money through loss of business, SLA breaches or regulatory fines but there is also a potential loss through reputational damage and share price devaluation.
How does AIOps help?
There are 3 functions that AIOps tools provide that help address these 5 issues (and incidentally if the tools you are being offered don’t help in these 3 ways then perhaps it’s time to look elsewhere).
Data – Firstly, an AIOps platform needs to be able to aggregate large amounts of data in a single format and place. This data typically comes from the following areas:
- Live and Historical Performance Data
- Real-time Alerts
- Network Data
- Incidents and Tickets
- Logs
- Chat
- And Possibly documents
The first 3 elements can be considered as traditional structured data, however, AIOps solutions should also be able to ingest unstructured data including chat and social feeds so that it can understand conversations between support engineers and intervene when it has a solution. The unstructured data must also include logfiles and tickets from service desks.
Machine Learning – Effective detection requires AIOps tools that are intelligent enough to set dynamic baselines that allow the tools to determine what constitutes normal activity under given circumstances (such as the time of day), then detect data or events that do not align with the dynamic baseline. Also, AIOps detection should be able to use Multivariate anomalies which detect outliers based on a series of different metrics to detect whether overall behaviour is out of the ordinary. In more complex situations, multivariate methods rely on neural networks to model interactions between various metrics and make decisions based on them. By cutting through the noise and correlating operations data from multiple IT environments, AIOps is able to identify root causes and propose solutions faster and more accurately than humanly possible and therefore achieve faster mean time to resolution (MTTR). It’s important that Machine Learning provided by the AIOps tools is also traceable so that the users and stakeholders trust the new AI-powered recommendations and automations.
Automation – Lastly AIOps tools should give users the ability to use advice from the platform for each incident received. This advice should not be static, and the tool should be able
to learn continually so that algorithms can be tuned, or new algorithms can be created that will identify problems quicker the next time an issue occurs. Ultimately the tool should be able to execute the fix automatically or at least offer a solution that will fix any issue.
Gartner has suggested 4 stages to this process:
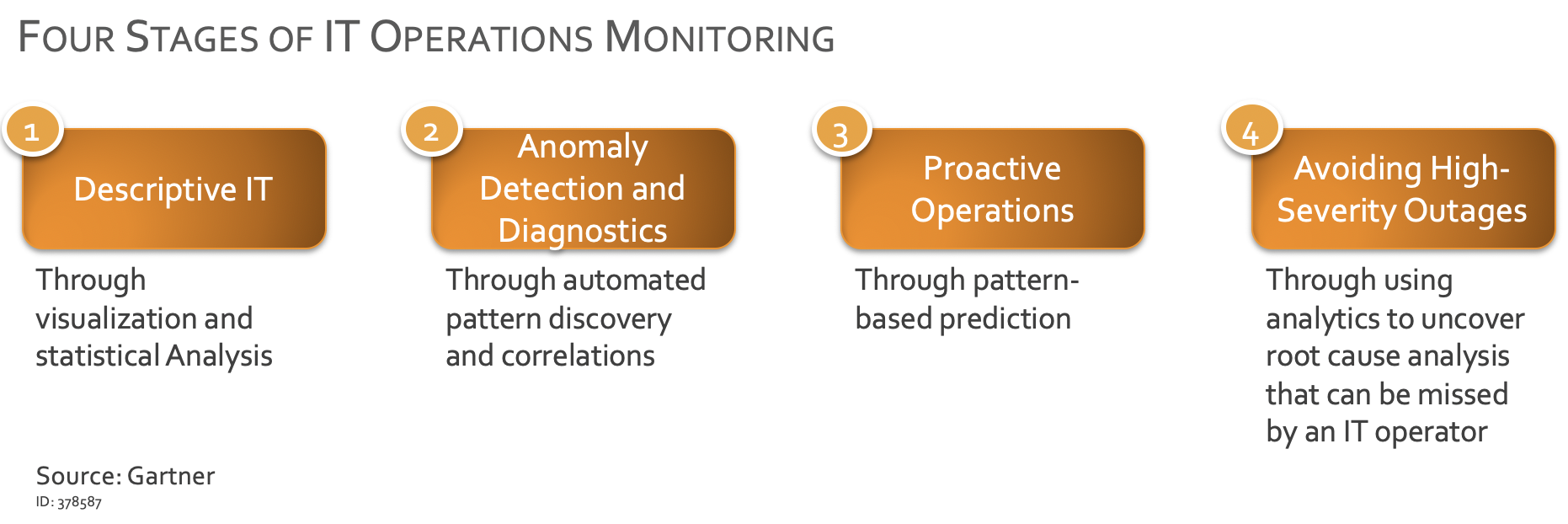
- If an issue is resolved then the solution is recorded in a knowledge base
- A problem can be matched to recurring problems based on a category and the resolution can be improved via crowdsourcing.
- The resolution is suggested based on a probability of what the resolution will be using AI.
- Finally trigger an automated response. Automated resolution may not be practical in all situations but AIOps should still provide insights that help lead to the resolution.
As the tools get more sophisticated and confidence grows, the problems that AIOps tools resolve automatically will increase.
What is Watson AIOps?
Watson AIOps has recently had its second release and at the same time IBM changed the way it will market their existing tools so it’s important to understand exactly what I am talking about when I mention Watson AIOps.
Watson AIOPs v1.0 was built on IBM Cloud Pak for Data however in version 2 this product has been renamed to AI Manager which in turn is part of a larger Watson AIOps v2.0 brand (or more recently IBM Cloud Pak for Watson AIOps). Most of what I’m talking about in this blog is AI Manager. Within this new Watson AIOps 2.0 brand you can now find Netcool Operations Insight which has been renamed to Event Manager. Similarly Predictive insights has been rebranded as Metric Manger. All this is explained very well in one my colleague’s blogs which you can read here and so I won’t duplicate that detail in this article.
The Cost of an Outage
The main issue we are trying to resolve with AIOps is the reduction in the number of outages and for those that do occur to be resolved as quickly as possible. To write any business case we need to know how much these outages cost the business. If we know that then we can start to understand if there is a business case that will enable Watson AIOps to pay for itself and over what time period.
As much as IT Ops leaders try, outages still happen. And when they do, they are expense and public. Every year, IT downtime costs an estimated $265 billion in lost revenue (Forbes). The difference between customer perception of the expected availability of their favourite applications and web sites and what is possible has never been further apart. While I was writing this blog (and the presentation before) there were 3 good examples of outages in Asia where I am based.
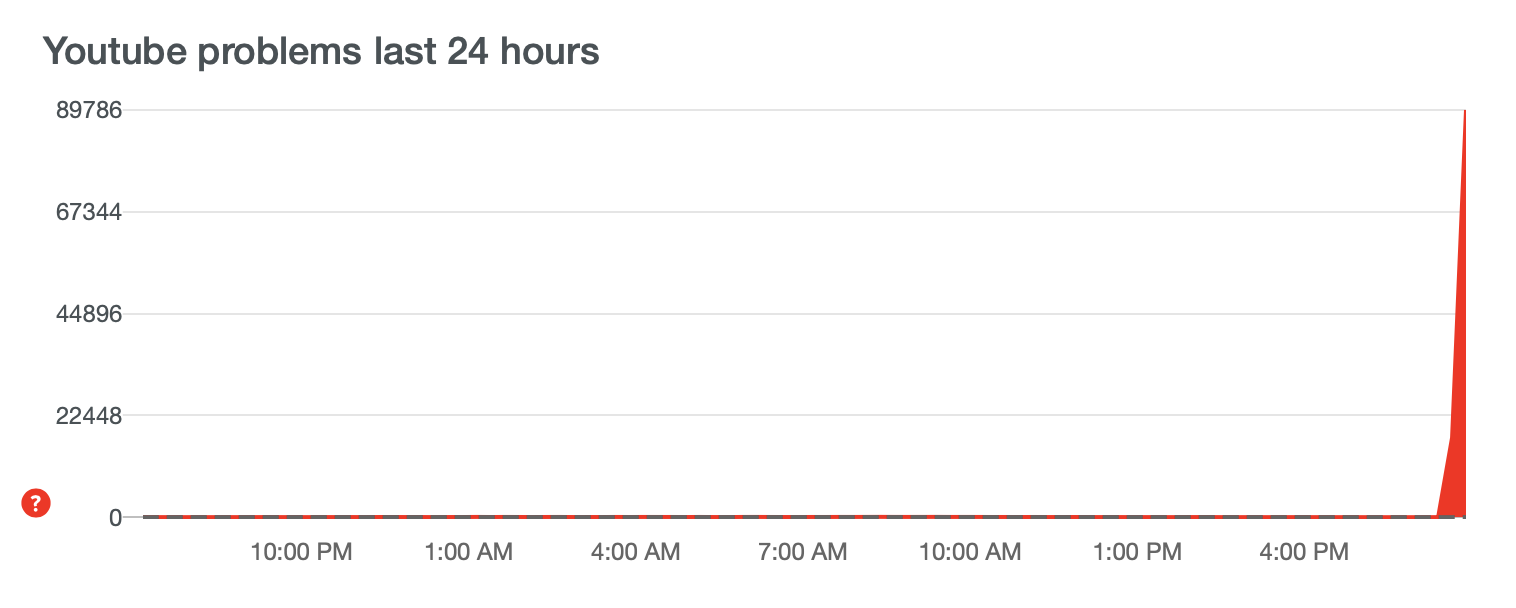
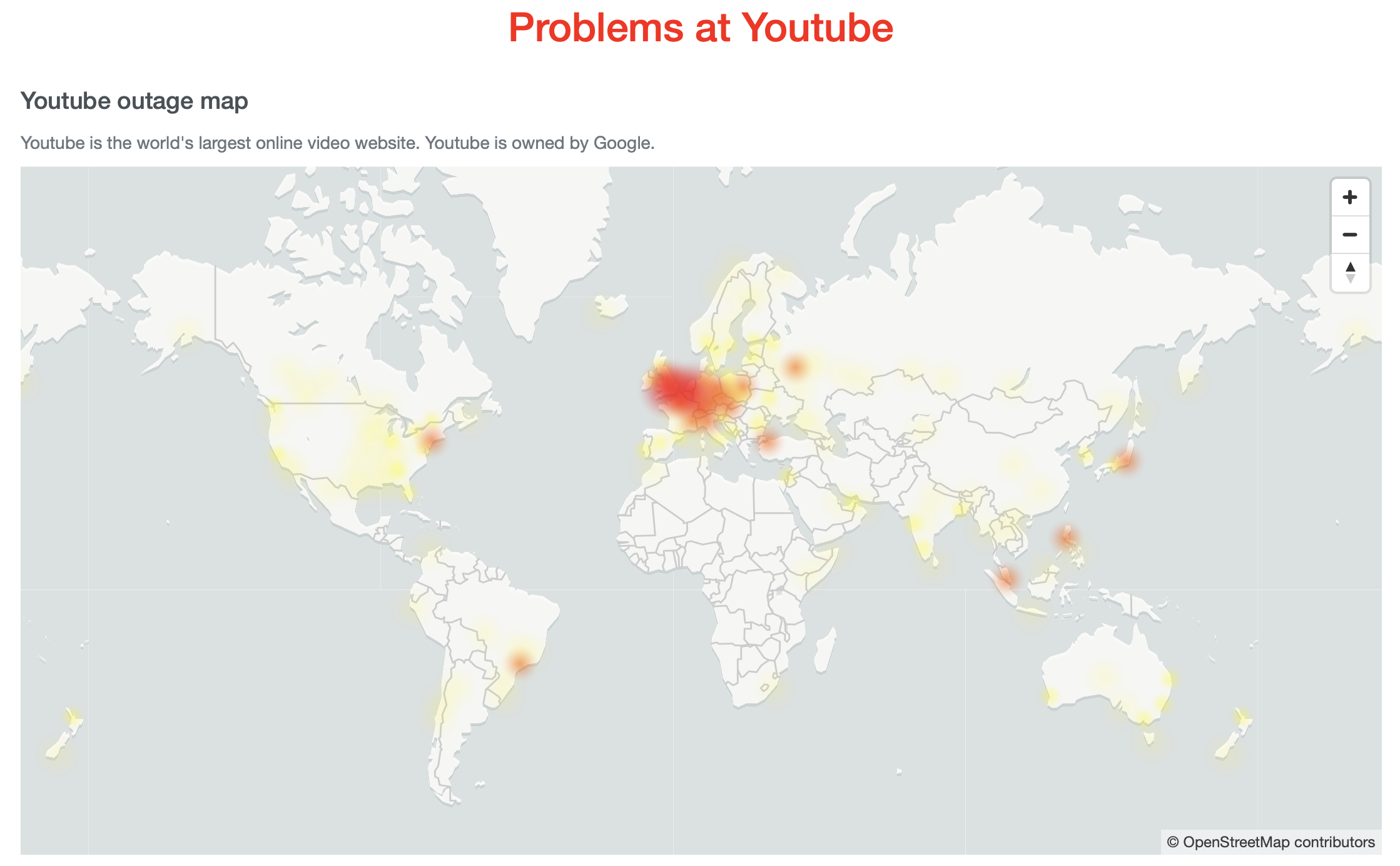
The first 2 both happened to Google. The first one was an outage with Gmail and the second one was a worldwide crash of YouTube which was unavailable for over 30 minutes. You can see from the graph that over 280,000 people were reporting it down to down detector at about 7 am.
 |
 |
All this happened on a platform that made $15.5 billion in revenue in 2019.
From these examples we can see that however much a company spends on IT there will be outages and the aim should not only be to make them as infrequent as possible but to recover from each outage as quickly as possible.
The third example was at the Tokyo Stock Exchange (TSE). The October 1st, 2020 outage was caused by a malfunction in a shared storage device that records information necessary for operating the trading system. The design was to switch to a backup but the switchover to the backup system had been set to “off” due to an error in the manual. This outage meant a 1-day closure for the stock exchange and a $30 billion cost in untraded stocks.
The last outage I will mention is the Facebook outage from 2019. The outage affected millions of users and lasted approximately 14 hours in the United States and even longer in some areas around the globe. It was caused by a simple server configuration change but this in turn triggered a cascading series of issues that brought down their whole platform. This is important because it not only affected the users of their platforms (Facebook, Instagram, Messenger, WhatsApp, and Oculus) with a cost estimated at $90M in lost revenue for the 14 hours it was down but it also damaged their reputation and led to a stock market price decrease of 2%.
The Business Case
How to get started
If you are writing a business case for any AIOps product then try and focus on the application that has had several outages in the recent past as these will hopefully have statistics you can use. Clearly if you have an application that has never had any downtime the case will be hard to prove.
Generally, the best type of application for an AIOps business case is a web-based customer focused application, better still if it is cloud or hybrid cloud. Lastly when you are choosing the application try to choose one that will benefit from AIOps – which means you should choose one that has logs, alerts and tickets. Once you have chosen the application or applications for the business case you need to think of the economic benefits gained i.e.
- What is the impact on revenue, if any?
- What is the impact on costs?
- If employee efficiency is a factor, will the headcount actually be reduced?
- Are there any one-time pickups of cash or reductions in capital needs?
- Is the benefit realised one time or on a recurring basis?
Service Affecting Incidents
Next you will need to look at how many incidents the application you have chosen has had and over what time period i.e.
- How many incidents have you averaged every month?
- How many of these were Severity 1 (for this I am defining Severity 1 as End user or customer impacting).
When I was doing my research for this blog I found some information from Quocirca Research. The numbers they presented are (I think) quite high and so when I go through an example later I will use much more conservative numbers however I have included them here anyway.
| Size of Company | Number of Incidents per Month |
| Enterprise-wide | 1208 |
| Large | 2749 |
| Medium | 1049 |
| Small | 650 |
| Very Small | 392 |
| Size of Company | Number of Severity 1 Incidents per Month |
| Enterprise-wide | 5.1 |
| Large | 8.9 |
| Medium | 6.3 |
| Small | 4.3 |
| Very Small | 2.8 |
Once you know how many incidents your applications have had you will then need to work out how much each one cost. This is based on the following factors:
- How much does it cost if your customers cannot transact?
- Were there regulator fines or SLA penalties?
- How many FTEs & how many hours did it require to get back online after a Sev 1?
- Do you need to spend additional resources on failover or back-ups because of the incidents?
- What is the impact to customer life-time value (more on this later)?
Again, Quocirca Research have some example figures, but these will depend on the size of the business and the amount of business that goes through that application. One interesting point they found is that LoB / Business cost is typically an incremental 2.9x on top of IT’s costs, scaling down with increased size.
Example Severity 1 Incident
To illustrate how these statistics can be incorporated into a business case I will work through a simple example for a small company. This fictional company makes a good profit from selling discounted Train tickets which is their one main application. They use Humio for logfiles, ServiceNow for tickets, Netcool Event Manager for Alerts (which is fed by Instana) and Slack for their collaboration tool. Their web-based application is based on a microservices architecture made up of 30+ microservices and leverages several programming languages and frameworks.
This example shows the lifecycle of a severity 1 incident before AIOps.

- The first sign of an issue is when the operator gets a call from a user and after analysis finds there is a real issue. After 1 hour on the phone with the customer he passes it to first line support.
- First line support performs all their normal checks and after 3 hours passes it to the DBA as they suspect a database issue. At this point the manager of the team is also called and gets involved.
- The DBA spends 2 hours looking at the issue unsuccessfully before she liaises with application support who in turn passes it after a few hours to development.
- Development realizes that one of their recent changes has created the issue and initiates a roll-back to an earlier working version.
In total the application was down for 13 hours and the 6 members of staff spent 31 hours working on the issue in total.
There were 3 costs associated with this outage to this:
- Staff costs during the incident and after the incident analysing the issue.
- Loss of business for the 13 hours the application was down.
| Single Incident | Without AIOps |
| Number of FTEs involved in an incident (average is 6.2) | 5 |
| Number of Hours on Sev 1 Incident | 31 |
| Number of hours service unavailable | 13 |
| Number of Hours spent verifying post incident | 18 |
| Average Staff Cost per Hour | $71.88 |
| Staff Cost | $3,522.28 |
| Loss of Business (per hour) | $1,095.89 |
| Loss of Business | $14,246.58 |
| SLA Impact Costs | N/A |
| Total | $17,768.85 |
- There is also a hidden cost that will be reflected in the Customer Lifetime Value (CLV). To keep things simple, I’ve only made a small adjustment to the churn rate of the customer from 60 to 62% but even this minor alteration drops the CLV by over 2 dollars. This suggests that retaining your existing customers is vital to your business. Losing long term customers due to downtime will affect long term profits.
| Average Order Value (AOV) | 25 | 24.94 |
| Purchase Frequency (F) | 2.67 | 2.67 |
| Gross Margin (GM) | 0.53 | 0.53 |
| Churn Rate | 1.61 | 1.61 |
| Customer Lifetime Value | $56.99 | $56.75 |
The definition of Customer Lifetime Value is simple: Customer Lifetime Value represents a customer’s value to a company over a period. There is a good description of Customer Lifetime Value and how to work it out here. Put simply it is the following:
LTV = AOV * F * GM * 1/CR
How does Watson AIOPs help?
Now we are going to look at the same issue with the train ticket application but this time using Watson AIOps. To do this I will break the incident down to 4 parts for which Watson AIOps offers some assistance in saving time and ultimately money.:
- Detect
- Isolate
- Fix
- Verify/Resolve
Detect
Incident Receipt
Firstly, we will look at the initial incident detection which is critical to resolving issues quickly.
There is a growing trend towards not using dashboards (watch out for a future blog on the death of dashboards) and Watson AIOps is one of the first IBM products to integrate with existing collaboration tools rather than impose yet another dashboard or GUI on your support staff. As a result, IBM have made Watson AIOps as an open platform meaning that incidents are sent to tools such as Slack and Microsoft Teams. This means that the incident comes directly to the support person on their standard desktop tools.
Logfiles
Secondly Watson AIOps can analyse and parse logs in any arbitrary format, and using neural nets learn what the messages mean after a training period. This means there are no static thresholds to set and no manual rules to define and manage. Watson AIOps doesn’t collect the logs itself but integrates with logging tools such as Splunk or Humio. In a recent IBM POC, the detection went from 2 hours 24 down to 7 minutes. This took 4 days to train and used logs and tickets.
Key Information
Watson AIOps gives you a succinct report of key information which leads to fast and accurate identification of the faulty component and leads to rapid incident detection. With each new incident you see:
- A notification that there’s a problem happening that needs attention under Title and Description
- A pointer to where the problem is and other services that might be affected under Localization and Blast Radius
- Synthesized evidence and advice to diagnose and resolve the situation under Relevant Events
 Without Watson AIOPs, getting to these actionable insights would mean manually working through pages and pages of high priority alerts that were more noisy than helpful.
Without Watson AIOPs, getting to these actionable insights would mean manually working through pages and pages of high priority alerts that were more noisy than helpful.
Isolation
After detection Watson AIOps provides a clear view with all the key signals related to the system fault to help isolate and fix the fault. The tool shows complete details on the specific message patterns, entities and timestamps to focus on, and gives links to the specific vendor tools to do more details investigation. Watson AIOps links together the relevant events you need to resolve the incident using association rule-learning, temporal, spatial clustering and other Machine Learning to reduce event floods and accelerates incident diagnosis.
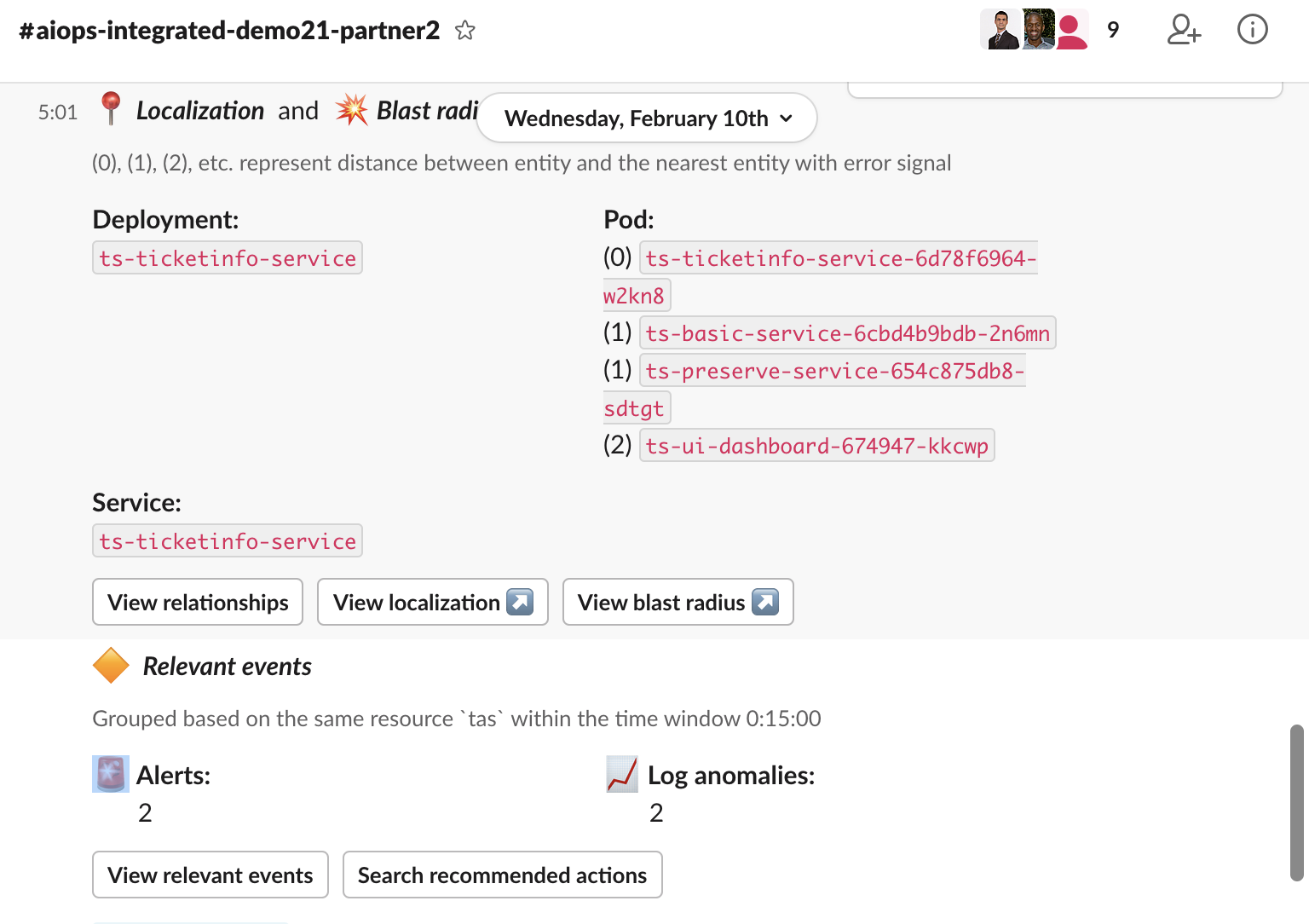
If you click on the View relevant events button in Slack you see the alerts and log anomalies that were grouped to create an incident. These can be hovered over to get more details or clicked on to get more details. Every insight is traceable, creating confidence in the data.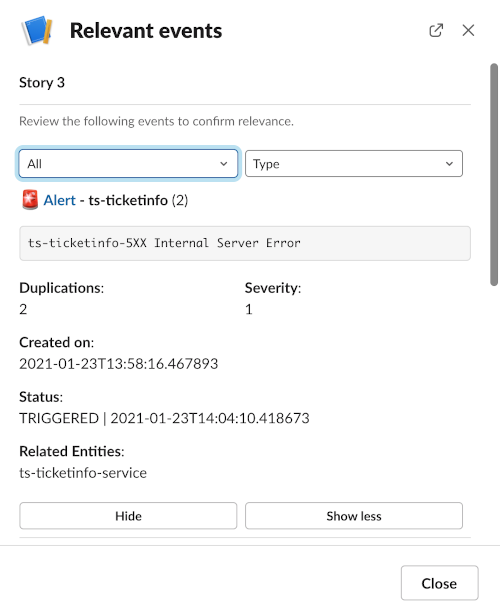
In the example, clicking on the Alert link will launch the Netcool Event Manager to show the events in more detail. Event Manager makes it simple to see related events together and isolate the emerging issues in a few clicks. In addition, the Events view shows you the Probable Cause marked with a blue percentage indicator. The higher the percentage, the higher the probability that the specific event is the probable cause.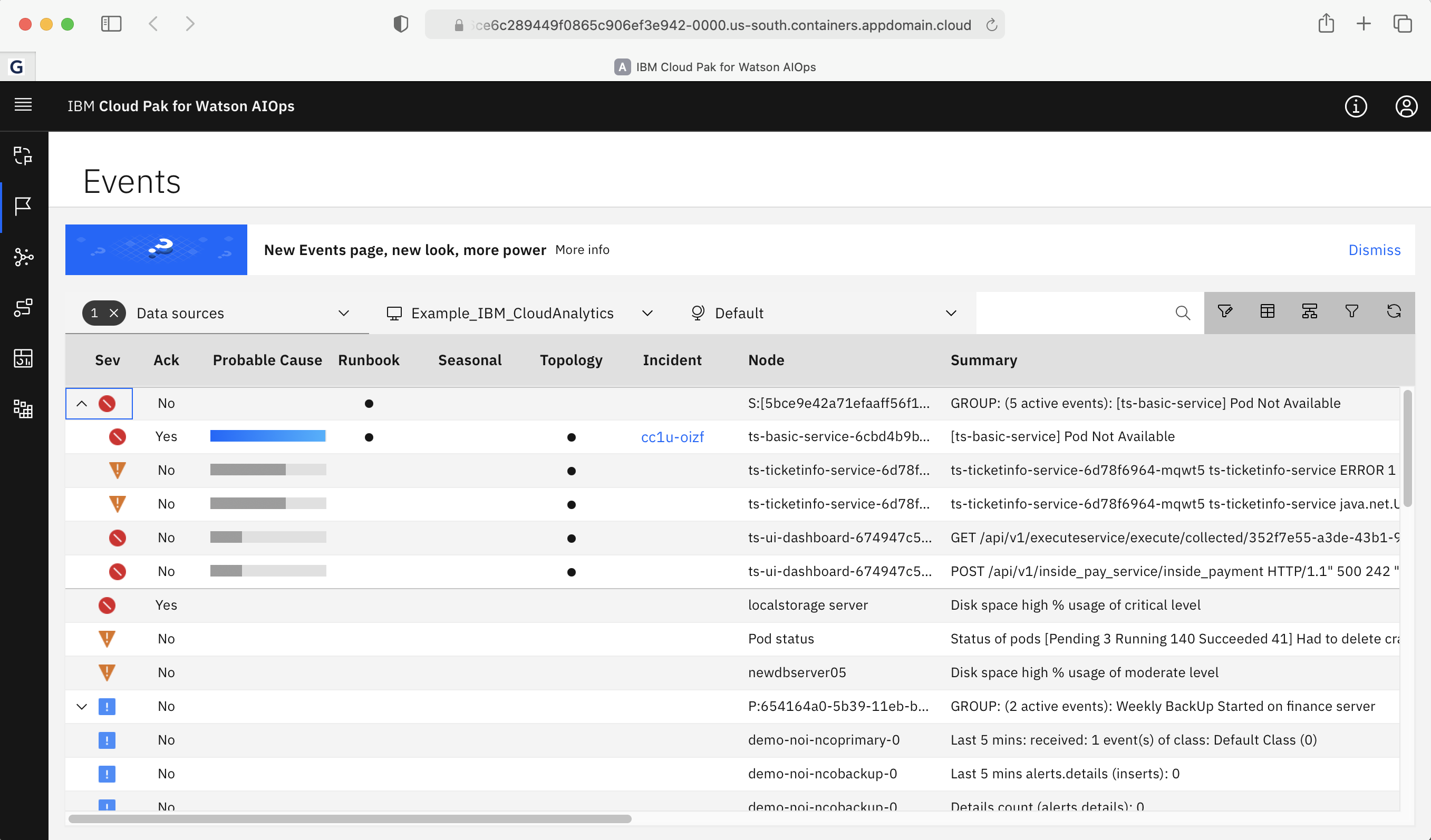
Notice that there is an event indicating that the ticketinfo service is unable to connect to ts-basic-service. This is the same information that we can see in the topology service in Event Manager, or directly from Watson AIOps by clicking on the Localization and Blast Radius buttons in the slack message.
- Localization suggests the originating entity of the problem that is associated with an incident and has the ability to show the historical time point of the incident by sliding the blue bar. This is useful as you can see exactly when each element was affected.

- The Blast radius shows the potential area of impact of the incident, containing likely affected entities.

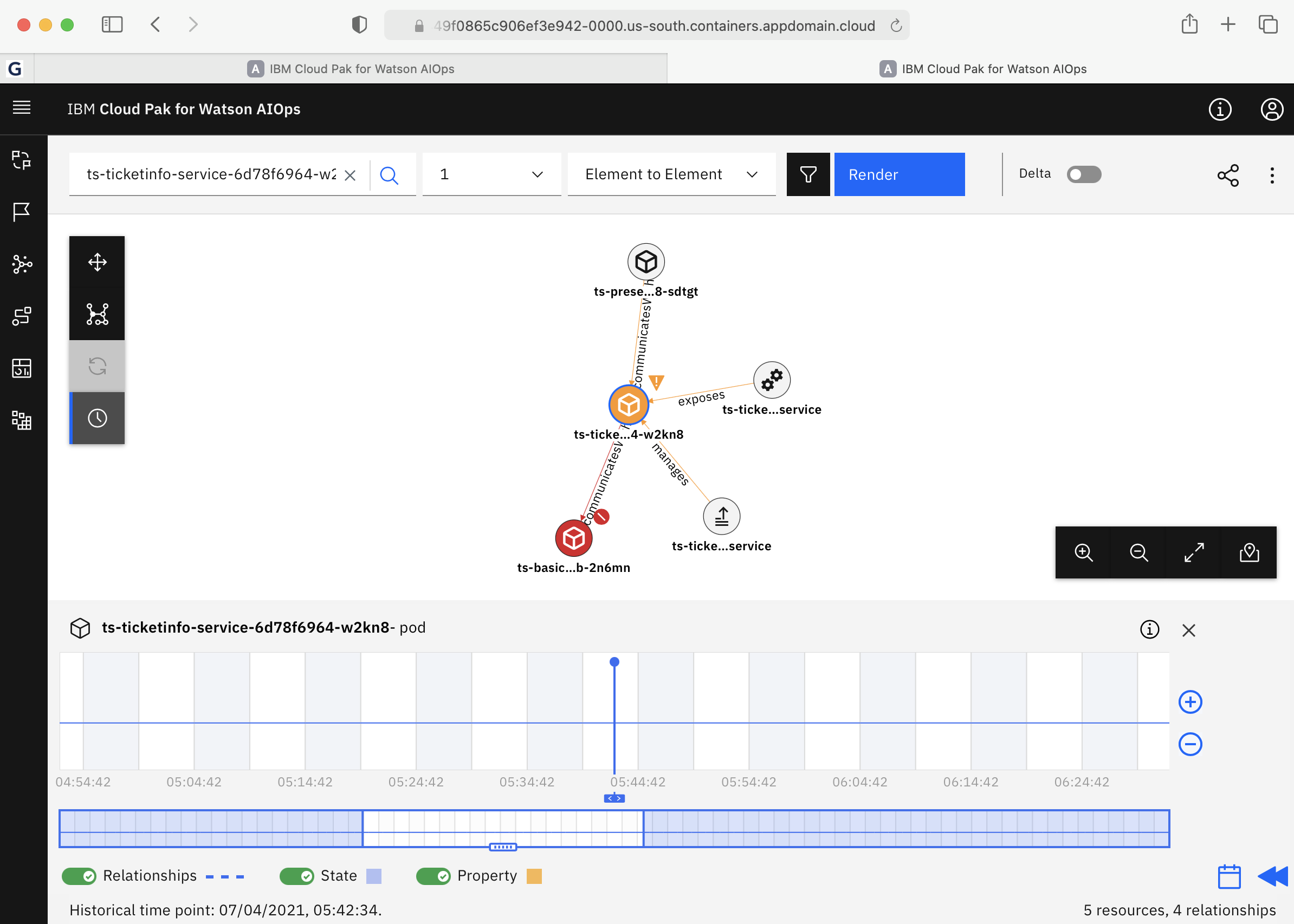
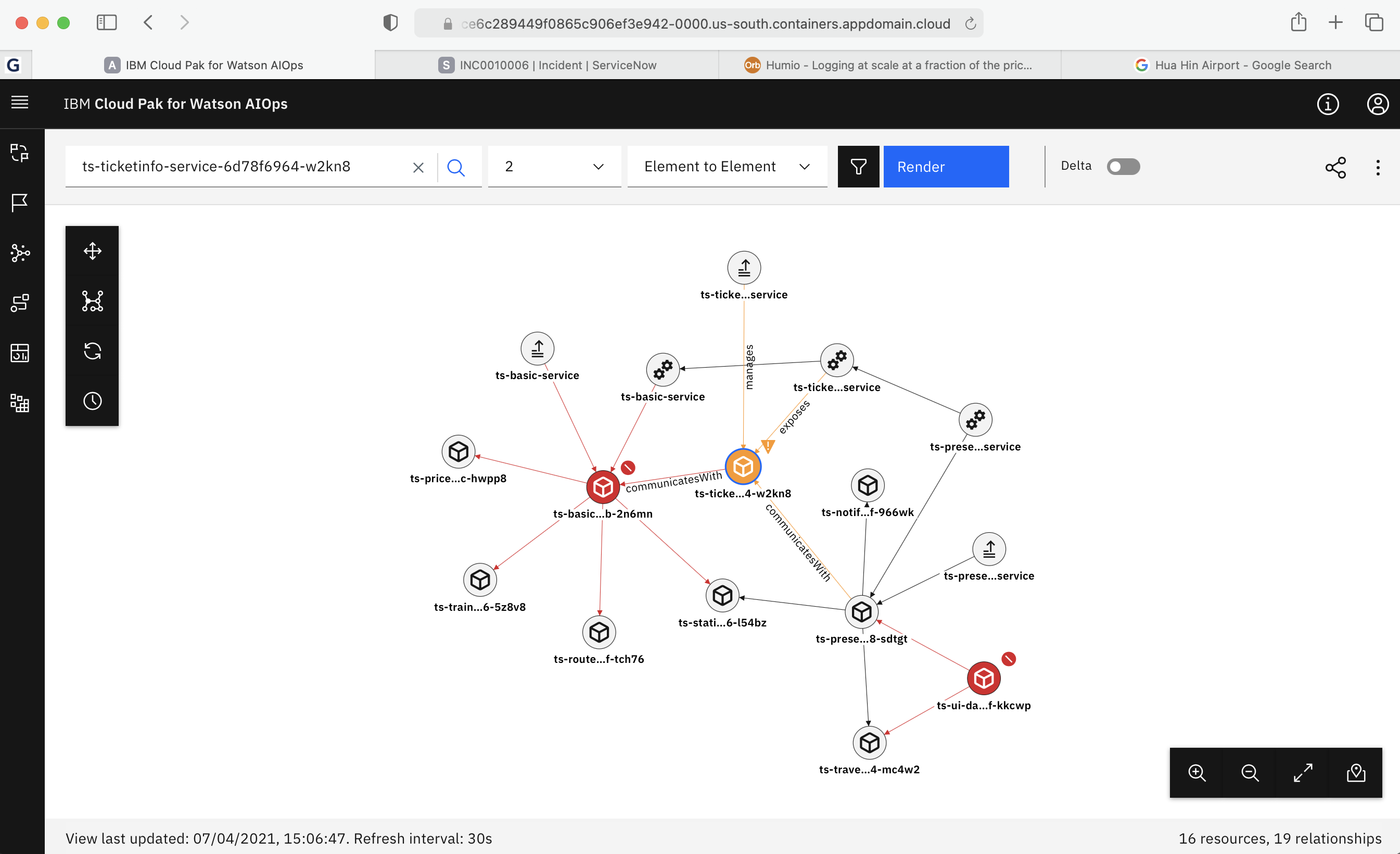
Fix
Using the Event Manager view we opened earlier, you can see that an event may be associated with a possible fix using a runbook. This functionality is included with the Event Manager product and not AI Manager but if you are a Netcool customer already this should be available to you either in your current package or through a trade up option at renewal. If not we have a blog about integrating Netcool with the free version of Ansible which you can read here. In this specific case there is a suggested runbook that redeploys the service to fix the issue. Executing this runbook in this example works successfully and the service is restored in 4 hours.
Verify
Lastly we can also use Watson AIOps to verify the fix by allowing us to identify similar incidents using Natural Language Processing (NLP) techniques to extract actual phrases from past tickets and chat. This allows the SME to respond with a more effective next-best action and accelerate the time to resolution. In this example the details are matched against ServiceNow tickets from which it will automatically extract a resolution action. This is achieved by pressing the Search Recommended Actions button. In it you can see it has pulled 3 possible resolutions which we can add to the story. You can see that potentially the second action is similar to our resolution and so may give us confidence that what we have done is the correct resolution. In any case we can add this to the Story and let other SME’s have a look at what we have found.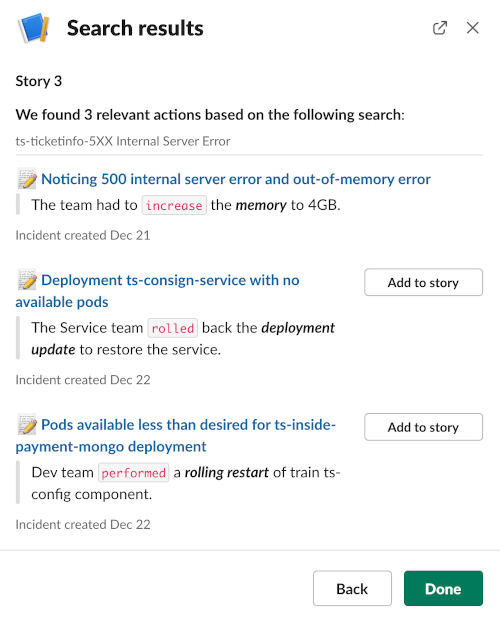
This intelligence helps the user to resolve the root cause with your team and ensure this issue never happens again.
Financials
Now let’s look at the financials once again. In our example the 13-hour down time is reduced to about 4 hours. The reason for this is as follows:
- With AIOps each part of the incident is quicker, and less people are involved.
- The incident is detected in a shorter time to diagnose and resolve.
- Less effort and skills are required.
- There is a reduced risk of detected anomalies evolving into a client impacting outage.
- And the longer you have the Watson AIOps the more the intelligence is built up until hopefully incidents are being resolved automatically in real-time.
Let’s analyse the figures once again.
| Single Incident | Without AIOps | With AIOps |
| Number of FTEs involved in an incident (average is 6.2) | 5 | 1 |
| Number of Hours on Sev 1 Incident | 31 | 4 |
| Number of hours service unavailable | 13 | 4 |
| Number of Hours spent verifying post incident | 18 | 5 |
| Average Staff Cost per Hour | $71.88 | $71.88 |
| Staff Cost | $3,522.28 | $646.95 |
| Loss of Business (per hour) | $1,095.89 | $1,095.89 |
| Loss of Business | $14,246.58 | $4,383.56 |
| SLA Impact Costs | N/A | N/A |
| Total | $17,768.85 | $5,030.51 |
Based on the reduction in hours the cost of this incident drops to about $5000. Most importantly the downtime drops from 13 hours to 4 which not only reduces this cost but makes the chance of the Customer Lifetime Value dropping reduce.
We will assume that our fictional company has 6 sev 1 outages per year and 150 incidents that do not result in a loss of business. This is much less than the Quocirca figures we looked at earlier which were 650 incidents and 4.3 sev 1 incidents per/month for a small environment
- Assuming these figures the costs over a year of these incidents is $268,334.54
- Assuming the same number but with quicker detection and resolution our new cost is $62,727.38
| Annual Costs | Without AIOps | With AIOps |
| Yearly Sev 1 Incidents | 6 | 6 |
| Severity 1 Total Cost Per Year | $106,613.12 | $30,183.06 |
| Yearly Low Severity Incidents | 150 | 150 |
| Staff Hours for Low Sev Incidents | 15 | 3 |
| Cost for Low Sev Incidents | $1,078.25 | $215.65 |
| Annual Cost for Low Sev Incidents | $161,737.24 | $32,347.45 |
| Total Cost for Incidents | $268,350.36 | $62,530.51 |
| Annual Saving | $205,819.85 |
Understanding what else you need to buy
The most important point when looking at AIOps is that a good tool should not try and replace all your current products but instead use them as inputs. Because of this an early phase of the business plan is to analyse what tools you already have that can provide the data that AIOPs uses. This should be for both structured data (e.g., metrics, alerts) and unstructured data (e.g. logs, tickets, chats). Gartner have helpfully created an AIOps model which you can use to overlay your current products. It’s a generic diagram but shows an overview of a complete solution.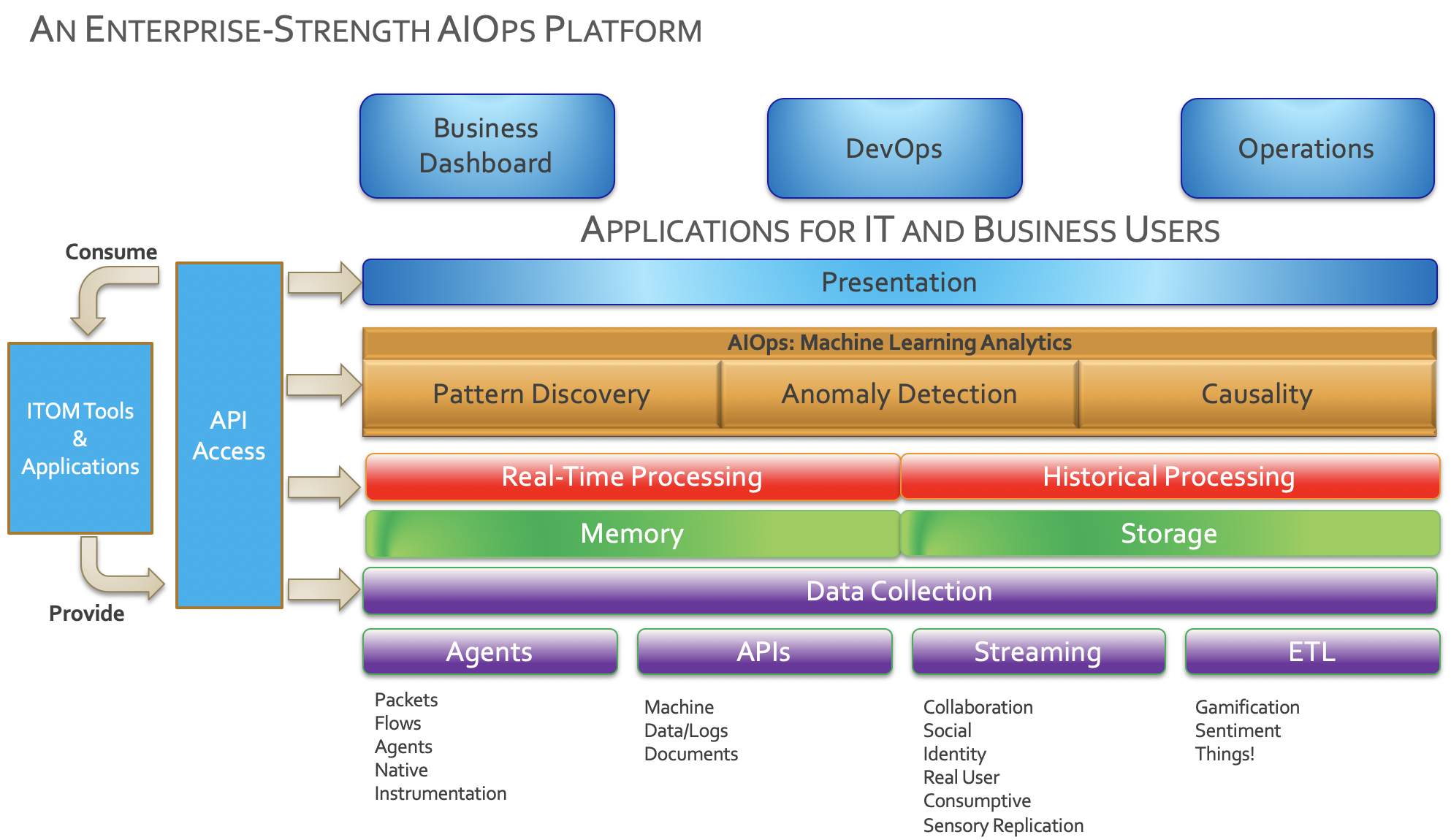
If you would like to talk further about any of the details in this blog then please reach out via email at simon.barnes@orb-data.com
Views: 1378