
It’s not often that I get excited about feature enhancements introduced by fix packs, possibly not since ITM 6.3.0.5 introduced the ability to run ad-hoc scripts for data collection from the OS Agents. Fix Pack 21 for Netcool Impact v7.1 is one of those rare occasions! The Fix Pack delivered a new feature that will significantly simplify future use of the “Get Update Events” option for OMNIbus Event Readers.
IBM have documented through various Tech Notes over the years the pit falls of configuring an OMNIbus Event Reader map to “Get Updated Events”. In a busy environment, or during an event storm, there is the potential for multiple instances of the same events to be present on the Event Queue. Policy development must take account of this and may need to include logic to set flags on the event, query the event queue, delete instances from the event queue and query the state of the event in the ObjectServer. In an already busy environment this has an unnecessary performance overhead in addition to the development overhead.
The basics of the issue are that in a busy environment, an event that has already been read by the event reader and placed in the EventQueue may not have been processed before the next polling cycle for the event reader. If the event in the ObjectServer has been updated before that next cycle, for example deduplicated, then the event StateChange time will have changed and will be returned once again be the event reader and placed on the queue. Two instances of the same event on the event queue to be processed by the same policy. The results may be innocuous, for example the event being enriched twice with the same data. However, undesirable results could occur, for example, an event escalated multiple times opening duplicate tickets or sending multiple emails. Policies must be designed to manage such conditions.
The Netcool Impact v7.1 event reader has always had the built-in functionality to manage an “ImpactFlag” column to indicate when an event has been processed. But that update occurs AFTER the policy has executed, and so it does not help manage the above scenario.
The new feature for an “ImpactReadFlag” updates a column immediately on reading it from the ObjectServer. If this same column is used within the event reader “restriction filter” it is designed to prevent re-reading events without the need to manage the scenario in code within policies.
Event Life Cycle
Before we discuss the use of the new property, let’s first review the basics of an “Event Life Cycle”. All Nectool environments need a defined “Event Life Cycle”. An Event Life Cycle identifies the stages of processing that are applied to an event following insert into the ObjectServer, it ensures that automations run in the correct order where there are dependencies.
A basic event life cycle may include the steps:
- Enrichment: Adding data to the event to give context to the issue. This is usually driven by data from an external CMDB.
- Suppression: Suppression of events from systems that are not operational, that may be systems that are temporarily in a maintenance state or a more permanent non-operational state, for example in-build or stored.
- Automated Response: Execute an automatic resolution response to the event, for example via Run Book Automation. Alternatively, such run books may be under the control of the Operators.
- Escalation: Escalation may be as simple as displaying the event to the operators via a Web GUI event list, or escalating via external applications, for example ticketing the event.
- Resolution/Clearing: Default ObjectServer automations correlate Problem and Resolution events to clear the problem events. Ticket closure may also drive event clearing along with standard ObjectServer extensions for housekeeping.
Generally, these stages need to be processed sequentially. The suppression, automated response and escalation stages will likely be dependent on the enrichment data. Escalation should not occur if the event is from a system under-going maintenance or not in an operational state, or the issue is resolved by an automated response. The new “Read Flag” assists in the management of that processing but will likely also require one or more flag to identify the next/current processing stage.
How to Use the Impact “Read Flag” Feature
Firstly, ensure a minimum of FP21 for Netcool Impact v7.1 is installed. However, I’d recommend FP22 as FP21 broke the management of the “ImpactFlag” column mentioned earlier, plus FP22 introduces filter-level options for the read-flag.
One or more new integer columns will need to be added to the Objectserver. The default name for the read-flag is “ImpactReadFlag”. The below example will also use a column “ImpactStageFlag” to indicate the next/current processing stage.
-- Create ImpactReadFlag column
alter table alerts.status add column ImpactReadFlag int;
go
-- Create ImpactStageFlag column
alter table alerts.status add column ImpactStageFlag int;
go
The combination of these flags will identify the status of a specific event, as an example:

One or more policies will need to be developed to manage the various stages of the event life cycle. Those policies will need to update the value of the column “ImpactReadFlag” and “ImpactStageFlag” at the end of the code:
EventContainer. ImpactReadFlag=Int(0);
EventContainer. ImpactStageFlag= Int(EventContainer.ImpactStageFlag + 1); ReturnEvent(EventContainer);
The “Event Mapping” settings in the new “OMINbus Event Reader” will need to include entries for each policy with the “Restriction Filter” including a clause for the required read and stage flags, for example, “ImpactReadFlag=0 AND ImpactStageFlag=1”.
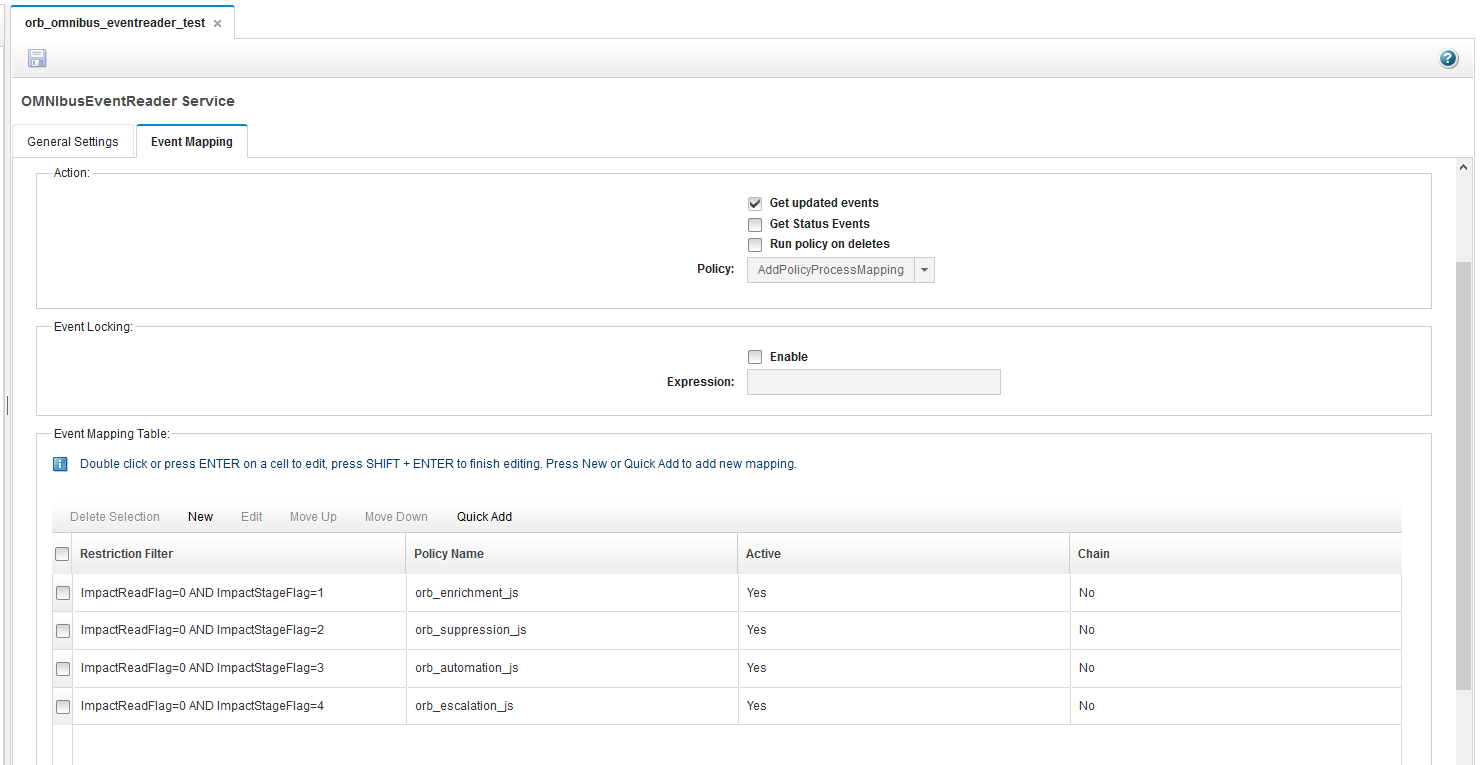
Care must be taken to ensure that all fields used by the restriction filters and policies are added to the “Selected Fields” list. Some internal fields are also required. Failure to do so can result in scenarios where the events are read from the ObjectServer but never arrive on the EventQueue, with no errors being logged. The “Optimize List” button will help here.

Before starting the event reader some manual changes are required in the Event Reader properties file. From a terminal session, edit the properties file for the event reader, “<ImpactServer>_<LowerCaseEventReaderName>.props” in the path $IMPACT_HOME/etc, and add the properties:
grep updateforreadevents $IMPACT_HOME/etc/NCI01_orb_omnibus_eventreader_test.props
impact.orb_omnibus_eventreader_test.objectserver.updateforreadevents=true
impact.orb_omnibus_eventreader_test.objectserver.updateforreadeventsexpr=ImpactReadFlag\=1
The first property enables the read-flag feature, the second defines the update made immediately after the read update (before the event is sent for processing). Note that the second line in the above example is superfluous as it uses the default column name and value, however, it demonstrates the syntax used for the property if a different column name and/or value is required.
At this point the Impact Server requires a restart. The method will differ dependent in your standard process but may be a stop/start of the operating system service or directly from the Impact scripts.
#Restart via System-V Services
service nci stop
service nci start
#Restart directly via Impact Scripts
$IMPACT_HOME/bin/stopImpactServer.sh
$IMPACT_HOME/bin/startImpactServer.sh
Does it Work?
I tested the above solution simulating an event storm of 9,999 distinct events that were repeating for 20 iterations with a 1 second sleep. This placed significant load onto my test environment, a VMWare session running on my laptop! The fans very quickly started running.
Before I added the properties nearly 5,000 duplicate event instances were added to the event queue during the event storm. Nearly 500 events had 3 duplicate instances on the queue. This equates 13% extra event instances to process, a significant overhead on an already busy system.
The read-flag eliminated ALL the duplicates.
The following screenshot demonstrates snapshots of an event as it progressed through the stages of the life cycle. The changes occur too quickly to capture all states, and especially the updates to the “ImpactReadFlag”. Remember, the Operations Team would not see these intermediate states. Events would only be displayed to the Operations Team, if required, after all stages have completed.

Filter-Level Flags
The above example is a simplified version of an event life cycle. In a production environment it will likely be more complex, with Impact processes running in parallel alongside ObjectServer automations. Complex life cycles could be managed through the careful use of the two flags, but administrators and developers must ensure all automations use appropriate filters and update the flags appropriately.
If more granularity is required with the read-flag, then Fix Pack 22 introduced “Filter-level” flags. A read-flag can be defined for one or more restriction-filter in the Event Map to override the global setting for the event reader.
The filter-level event reader property names are very similar to those above but have the filter number appended to the end. The filter numbers are indexed from 1 upwards, and can be identified from the order in the Event Map UI or from the properties “impact.< LowerCaseEventReaderName >.restriction.#” in the appropriate event reader file. For example, managing events with two read-flags, named “ImpactReadFlag1” and “ImpactReadFlag2”, requires the below properties.
impact.orb_omnibus_eventreader_test.objectserver.updateforreadevents.1=true
impact.orb_omnibus_eventreader_test.objectserver.updateforreadeventsexpr.1=ImpactReadFlag1\=1
impact.orb_omnibus_eventreader_test.objectserver.updateforreadevents.2=true
impact.orb_omnibus_eventreader_test.objectserver.updateforreadeventsexpr.2=ImpactReadFlag2\=1
If these lines replace the entries from the previous example, then a read-flag will only be updated for filters 1 and 2. If the lines are added in addition to the previous lines, then filters 3 and 4 will be updated based on the previous logic, i.e. a read will set “ImpactReadFlag=1”. As yet I’ve not found it necessary to use the more granular read-flags, but I haven’t looked very hard. Where multiple parallel policies are running at a particular life cycle stage then it may come in useful.
Summary
This feature enhancements will certainly make future policy development easier and quicker, but, more importantly, there is less overhead on the environment at multiple levels: fewer policy queries to the ObjectServer, fewer events read by the EventReader, fewer writes by the EventReader and fewer event instances added to and updated on the EventQueue.
However, there is one minor negative, the property is not visible from the UI. Impact administrators need to be made aware that this feature has been enabled for a specific OMNIbus Event Reader as there is no indication from the UI. UI updates are still possible and will not remove the manually added properties, but if the administrator is unaware that the feature has been enabled (or exists), then issues could be introduced. This lack of UI visibility is also the case for the Impact processing flag, “ImpactFlag”, generally used when connecting an Impact cluster to an ObjectServer fail-over pair. That feature has been around for a number of years and has no UI option, so it’s unlikely that the new feature will have any UI presence soon. But, of course, all Netcool installations have extensive documentation that details the Event Life Cycle and architecture, so that is a minor concern?
Views: 658